How Do We Test Our Front-End Applications in Trendyol GO? (Part 2)
October 8, 2022
In our first article, we talked about how we organized the test flow for our micro-frontend application in the Trendyol GO Logistics-Delivery team, how we integrated this practice into our workflow on the way to TDD, and why we chose Cypress for the integration & E2E testing.
In this article, we will talk about what we did on the CI/CD side, what problems we encountered, and how we dealt with them while building such a process.
CI/CD Pipeline
After determining the modules and user flows we will write tests for, one of our first steps was creating the test infrastructure on the CI/CD side, using GitLab-CI/CD. At the end of the day, what we want to reach is not tests independent of the development; on the contrary, it is to do an intertwined practice our routine. For this reason, CI/CD processes must start when the first test code is merged into the main branch.
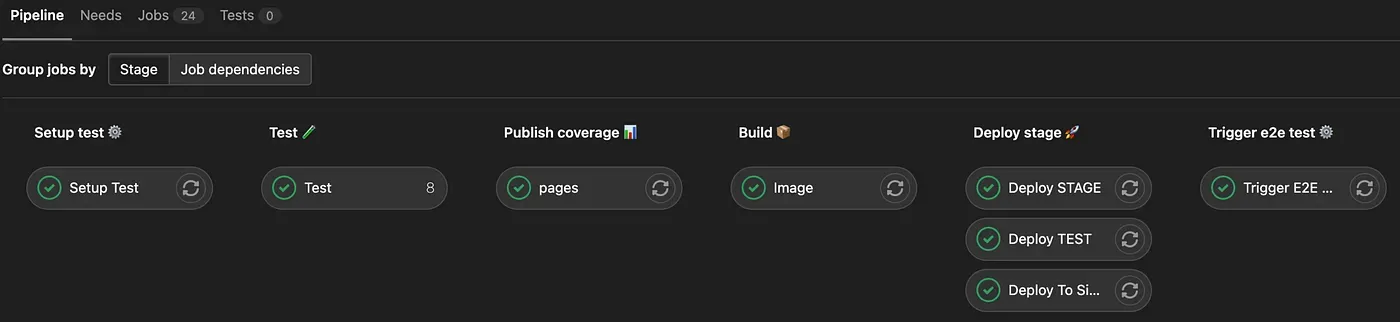
We put Setup Test as the first step:
- We use an image of Cypress that is compatible with the Node.js version we used in this project as the job runner.
- We install the packages needed by the project with npm install and cache them for use in later steps.
.test_integration_cypress_setup:
stage: setup test
image: cypress/base:14
cache:
key: $CI_COMMIT_REF_SLUG
paths:
- node_modules
...- We run our linter and formatter controls. If an error occurs outside the lint and format rules that we set in our code, we break the pipeline.
- We build the application to handle the coverage report creation.
- Many examples for Cypress are shown as integrated into monolithic applications. You will see that the application is run in development mode, and tests are run on top of that in those examples.
- Our application is designed as a Shell, with four micro-frontend applications. Since we chose to access the most up-to-date image of the Shell package on the pipeline, we had to get a build.
The second step we see as Test is the part where we run our integration tests:
-
Since our application is in the micro-frontend architecture, in this step, we associate the last successful image of the Shell application with the job under services and run it.
.test_integration_cypress_parallel: stage: test image: cypress/base:14 cache: key: $CI_COMMIT_REF_SLUG paths: — node_modules policy: pull parallel: 8 services: — name: blabla.com/shell:latest - command: [“node”, “server.js”] ... -
We also run the application to be tested and run the tests.
-
Here we run the integration tests in parallel. For example, at this step, we are currently running tests for the Logistics-Delivery domain micro-frontend application in 8 parallel processes. Around 700 isolated tests scattered across 75 spec files take 5–6 min. to finish.
-
Another thing we do here is to pass the partial coverage reports generated as a result of each parallel run to the next job in the pipeline with the appropriate job id for the coverage report we will create in the next step.
In
Publish Coveragestep, we merge the partial reports we collect from parallel jobs and create our final coverage report.
Finally, let's talk about the Trigger E2E Test step. After the application is deployed to the STAGING environment, we trigger a separate repo that we created using Cypress for E2E/smoke tests. E2E tests are running in parallel, utterly different from this process on that repo's pipeline.
Ultimately, we aim to reach a world where E2E/smoke tests test comprehensive user stories by hitting backend services. We can have hundreds of tests on the integration side; 10–20 user stories covering our domain will be enough for us on the E2E side.
Parallelization
I will talk about the parallelization techniques we used in the structure we created in a little more detail:
Cypress has a paid SAAS called Cypress Dashboard. Under normal circumstances, you must use this service to ensure parallelism in the tests you write with Cypress. When you use this, at the point where the tests start to run in the pipeline, each runner communicates with the remote Cypress service over REST, and that service determines which specs to run for that specific runner.
We did not want to use this paid service while we set up the infra. We looked at what we could use as an alternative and saw that there was a project called sorry-cypress. This project is being developed as an OSS and offers the advantage of using options to Cypress's services behind the paywall in your development environment.
sorry-cypress has many tools, like dashboard and director. We also used sorry-cypress's director tool for this job. We deployed the director application in our infra and used it to manage the parallelism in our Cypress test flows through the API it offers. director etermines which specs will pass to which runners over an ID set for that run.
There is one problem with sorry-cypress that we see from our own experience, and that is: while parallel tests are running when any job fails, the developer typically wants to run that specific failed test in that job but said mechanism does not yet exist. This causes a slight waste of time for the case where the tests fail.
https://github.com/sorry-cypress/sorry-cypress/issues/368
Coverage
In this step, we merge the partial reports we collect from parallel test jobs with's nyc tool and create an HTML report. We also serve this via gitlab-pages.
On the coverage report side, we have not yet implemented methods such as forcing certain thresholds and breaking the pipeline case-by-case basis. We use it mostly to see what we are doing and to guide us on how we can cover the missing modules & parts of our application.
We had two problems in the creation of the final report from partial coverage reports:
-
The
pathproperties of partialcoverage.jsonfiles generated in parallel processes must be the same as thepathin the publish job. For GitLab-CI/CD,pathvalues are formed over$CI_NODE_INDEXincoverage.jsonfiles created with the @cypress/code-coverage plugin in parallel jobs. This causes the wrong result to be produced during the merge.We manipulated all the
pathvalues for the solution according to the publish job..test_integration_cypress_publish_coverage_report: stage: coverage image: cypress/base:14 dependencies: — Test before_script: — mkdir coverage_dump — mv coverage-final_*.json coverage_dump/ — node cypress/util/replacePartialCoverageReportPaths.js coverage_dump ...replacePartialCoverageReportPathsis a simple Node script that traverses all partial coverage files and changes the path variables to the value used in the publish job. -
The second issue is about nyc. We saw that the local installation of this tool somehow could not merge partial files correctly. As a solution, we never moved node_modules to this step and preferred to run nyc with npx.
--- script: — npx nyc merge coverage_dump .nyc_output/out.json — npx nyc report — reporter=html — rm -rf public/* — mv coverage/* public/ artifacts: paths: — public
These are the steps we took and our experience in the integration & E2E testing of our front-end applications. We hope these insights will be helpful in your testing journey.
* This article was first published on https://medium.com/trendyol-tech on the specified date.